The modern data stack is a combination of cloud-native services and workflows that together let you:
The Modern Data Stack in 2026:
What It Is & Where Dataoma Fits
AI, personalization, and real-time decisioning all depend on one thing: a solid data foundation. That foundation today is the modern data stack. It’s not just another buzzword, it’s the practical set of cloud tools and practices that let teams move from raw events to reliable insights, quickly.
If you’re wondering what belongs in that stack, how it has changed in 2026, and where a platform like Dataoma fits, this guide breaks it down without the hype.
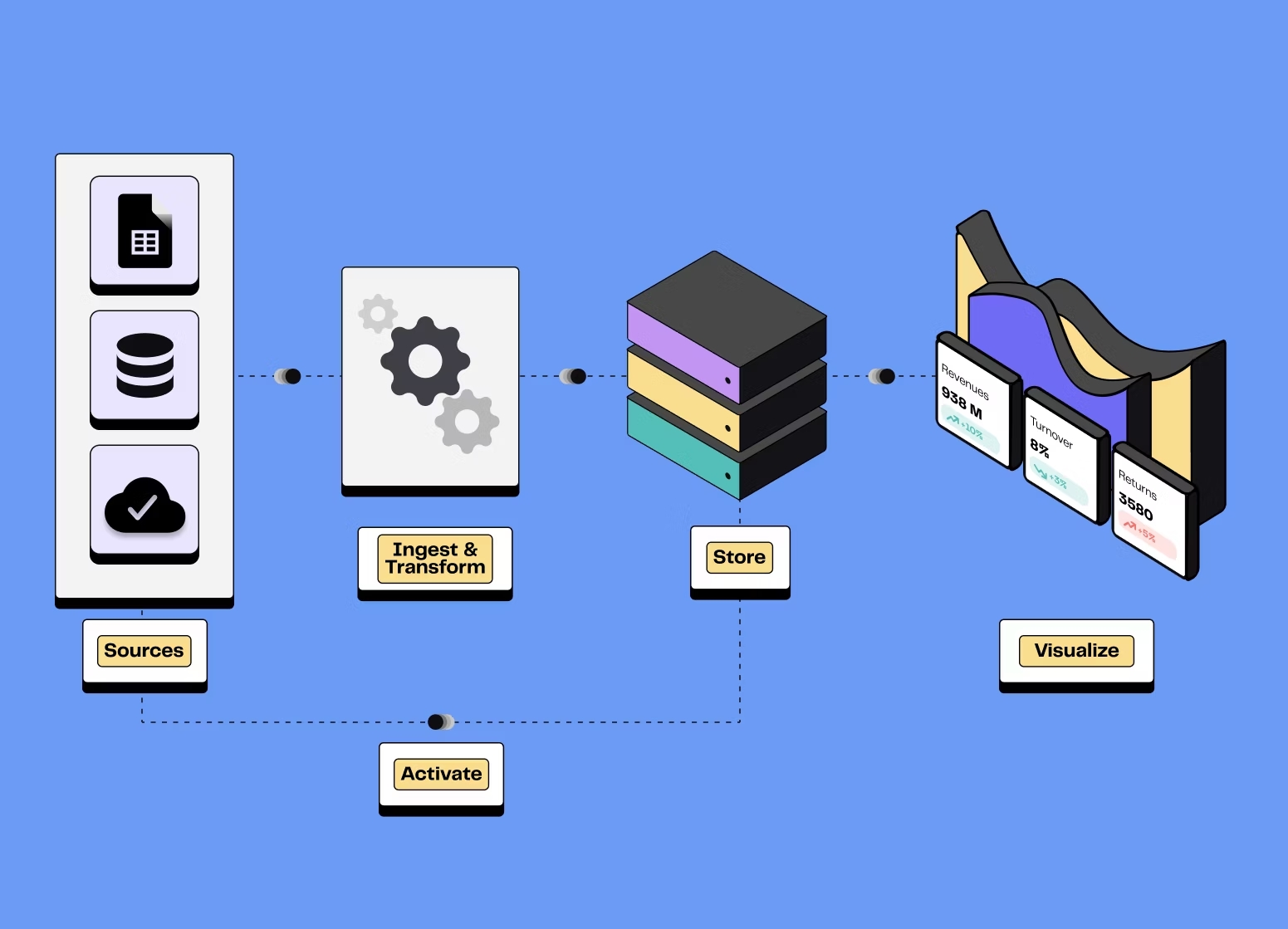
1. What do we mean by “modern data stack”?
• Ingest data from applications, databases, and events
• Store it in scalable warehouses or lakehouses
• Transform it into clean, modeled datasets
• Discover & document what exists and how to use it
• Test & monitor data quality over time
• Serve it to BI tools, AI models, and operational systems
In other words, it’s the end-to-end system that turns messy, scattered data into trustworthy inputs for analytics and AI while keeping governance and cost under control.
2. Core building blocks of a modern data stack
Exact tools vary by company, but the pattern is surprisingly consistent. Most modern stacks include:
2.1 Ingestion & integration
• Connectors and pipelines that move data from SaaS apps, databases, and event streams into your warehouse or lakehouse (e.g., Fivetran, Airbyte, custom CDC jobs).
2.2 Warehouse / lakehouse
• Cloud platforms that centralize storage and query compute (e.g., Snowflake, BigQuery, Redshift, Databricks).
2.3 Transformation & modeling
• ELT tools that turn raw tables into curated, analytics-ready models using SQL or code (e.g., dbt, Spark, Dataform).
2.4 Orchestration
• Schedulers that coordinate pipelines and dependencies (e.g., Airflow, Dagster, Prefect).
2.5 Discovery, documentation & quality
• Data catalogs and observability tools that help people find, understand, and trust data this is where Dataoma lives.
2.6 Analytics & activation
• BI tools and reverse ETL that surface insights and push them to business systems (e.g., Power BI, Looker, Tableau, Hightouch).
Where Dataoma plugs in: Dataoma connects directly to your cloud warehouse, profiles datasets for automatic data discovery, generates and centralizes documentation, and then uses that documentation to drive data quality tests. It acts as the discovery and trust layer of your modern stack.
3. How we got here: the evolution of the stack
The “modern” in modern data stack has changed meaning several times over the last decade and a half. A quick timeline helps explain the tools we see today.
Early 2010s – Cloud warehouses go mainstream
• Redshift, BigQuery, and Snowflake show that storage and compute can scale elastically in the cloud.
• Teams start moving away from tightly coupled on-prem appliances.
Mid-2010s – ELT and SaaS pipelines
• The shift from ETL (transform first) to ELT (load first) begins.
• Managed ingestion tools simplify pulling data from dozens of SaaS systems.
Late 2010s – Ecosystem explosion
• Orchestration frameworks, dbt-style modeling, and cloud-native BI tools arrive.
• “Modern data stack” becomes shorthand for this cloud-centric toolset.
Early 2020s – Self-service and streaming
• More business users access data directly through BI and notebooks.
• Real-time and micro-batch ingestion grow in importance.
2025–2026 – AI-first and data products
• Stacks are designed with AI workloads and data products in mind, not just reporting.
• Catalogs, observability, and documentation become non-negotiable for trust and governance.
4. Modern vs. legacy data stacks
It’s easier to see the value of modern approaches by contrasting them with older patterns.
Infrastructure
• Legacy: On-premises hardware, fixed capacity, expensive to scale.
• Modern: Cloud-native, elastic scaling, usage-based billing.
Data flow
• Legacy: Heavy ETL, long nightly batches, rigid schemas.
• Modern: ELT, streaming, incremental models, flexible schemas.
Access & collaboration
• Legacy: Centralized IT gatekeeping; slow to get new data.
• Modern: Self-service, governed access; multiple teams working in parallel.
Trust
• Legacy: Documentation scattered in wikis; little visibility into quality.
• Modern: Catalogs, profiling, and tests make quality and lineage visible.
5. Why invest in a modern stack?
Moving beyond legacy tooling isn’t just an IT upgrade, it changes what the business can do.
5.1 Handle growth without re-architecture
• Elastic warehouses and lakehouses let you ingest more data, add new sources, and support more users without rewriting the entire system.
5.2 Respond to the business faster
• New metrics or data products can be modeled and exposed in days, not quarters, so teams can adapt to changing markets and product needs.
5.3 Improve analytics productivity
• With clean models and a discovery layer, analysts and data scientists spend more time interpreting and less time spelunking in raw tables.
5.4 Build a healthier data culture
• When the stack is designed for self-service and trust, more people are comfortable using data,and fewer rely on screenshots or exported CSVs.
Dataoma’s contribution: Modern stacks only deliver these benefits if people can easily find and trust the data inside them. Dataoma gives you that navigational layer on top of the warehouse, auto-generating docs, and enforcing expectations with tests so self-service doesn’t devolve into chaos.
6. The modern stack as an AI backbone
AI and machine learning are only as good as the data they see. A well-designed modern stack provides:
• Scale: Cloud warehouses handle large training datasets without elaborate sharding.
• Freshness: Streaming and incremental loads keep features up to date.
• Consistency: Shared models and feature tables reduce “train/serve” skew.
• Governance: Catalogs and policies ensure training data respects privacy and compliance.
For AI use cases, it’s not enough to know that data exists, you need to understand its quality, distributions, and lineage. That’s exactly the kind of metadata and testing that Dataoma surfaces from your warehouse, giving ML teams more confidence in the inputs to their models.
7. Data products and domains on top of the stack
One of the major shifts in 2025–2026 is thinking of data not just as tables, but as products owned by domains (marketing, finance, operations, etc.).
What is a data product?
• A curated, reliable dataset or API designed to serve a specific purpose, like “Customer 360” or “Churn Risk Scores”, with clear SLAs, documentation, and owners.
How the stack enables data products
• Warehouses and modeling tools host and shape the data.
• Orchestrators keep refreshes predictable.
• Catalogs like Dataoma describe what the product is, who owns it, and how to use it.
• Tests and monitoring ensure products remain trustworthy over time.
This way of working dovetails with ideas like data mesh: decentralizing ownership while sharing a common technical platform and governance layer.
8. Building your modern data stack: a pragmatic path
You don’t need to adopt every acronym at once. A sensible rollout often follows stages like these:
Step 1 – Choose your central warehouse / lakehouse
• Select a cloud platform that fits your scale, skills, and budget.
• Establish basic environments (dev / test / prod) and security controls.
Step 2 – Standardize ingestion
• Use managed connectors where you can, and consistent patterns for custom pipelines.
• Prioritize critical sources first rather than integrating everything.
Step 3 – Introduce modeling and transformations
• Define core layers (raw → staged → modeled) in your warehouse.
• Version and test your transformations like any other code.
Step 4 – Add discovery & quality with Dataoma
• Connect Dataoma to your warehouse to automatically profile and document key tables.
• Turn this documentation into executable tests to guard against regressions.
Step 5 – Roll out analytics & data products
• Expose curated models to BI tools and domain teams.
• Use the catalog and tests as the foundation for production-grade data products.
9. Common challenges (and how to keep them under control)
Modern stacks solve many problems, but they also introduce new ones if left unchecked.
Tool overload
• Challenge: It’s tempting to adopt a new tool for every niche problem.
• Mitigation: Favor platforms that cover multiple needs and invest early in a central discovery layer so you can see what’s actually used.
Unpredictable costs
• Challenge: Consumption-based pricing can creep up through inefficient queries and unused workloads.
• Mitigation: Monitor usage, set guardrails, and regularly prune unused models and dashboards.
Data trust issues
• Challenge: Even in modern stacks, stale or incorrect data can erode confidence.
• Mitigation: Use tools like Dataoma to continuously profile data, surface anomalies, and run documentation-backed tests so issues are caught early.
Limited adoption
• Challenge: If only a small technical group uses the stack, you don’t get the full ROI.
• Mitigation: Invest in training, make the catalog the obvious entry point, and celebrate cross‑functional wins that came from better data.
10. Is the modern data stack for you?
You don’t need billions of rows or a huge data team to benefit from a modern approach. You’re likely ready if:
• You have multiple source systems and struggle to keep a single version of the truth.
• Analysts are building similar datasets over and over in different silos.
• AI or advanced analytics are strategic priorities, but data trust is low.
• On-prem systems are hitting scale, performance, or cost limits.
In those cases, a modern, warehouse-centric stack with a strong discovery and documentation layer like Dataoma can turn your data platform from a bottleneck into an accelerator.
Final thoughts
The modern data stack in 2026 is more than a list of tools. It’s a way of structuring your data platform so that:
• Raw data from many systems lands in one scalable, queryable place
• Transformations and models are managed like real products, not ad-hoc scripts
• People can discover, understand, and reuse what already exists
• Quality is monitored continuously, not checked once a year in a spreadsheet
Dataoma sits squarely in that last mile: it connects to your data warehouse, shines a light on what’s inside through profiling-based discovery, creates and centralizes documentation, and converts that knowledge into data quality tests that run automatically.
If you’re building or upgrading your modern data stack, adding this discovery and trust layer early makes everything else : analytics, AI, and data products, more reliable and far easier to scale.